In this article, I would like to share with you and the whole internet our experience of dealing with RabbitMQ Live updates. You will learn some details about our architecture and use cases. Let’s start from the simplest… Why do we need RabbitMQ in our business?
Our Architecture
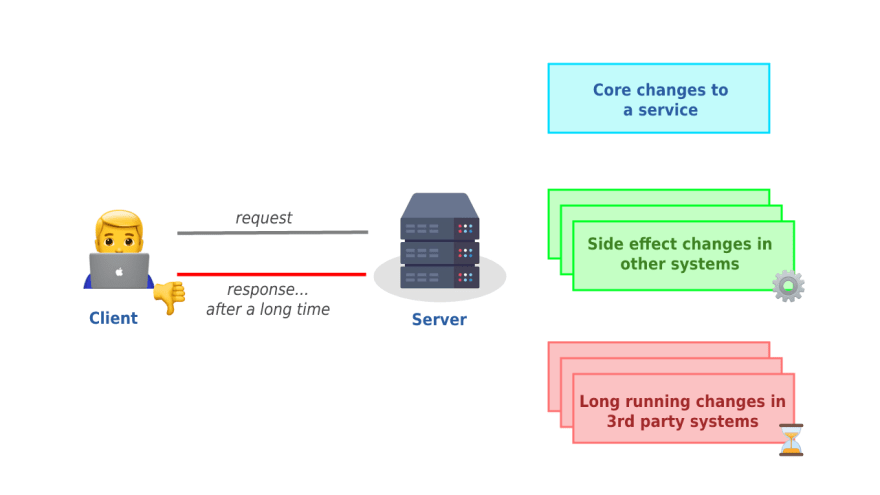
As a health insurance company, our business depends on many different third-party services to analyze risks, process claimable documents, charge monthly payments etc. All these processes take some time to be processed, so to keep our services fast and autonomous from each other, we are using asynchronous processing of tasks that can be done in the background. This approach speeds up responses and allows to do more in the background, ie. email sending, policy creation, acceptance verification etc.
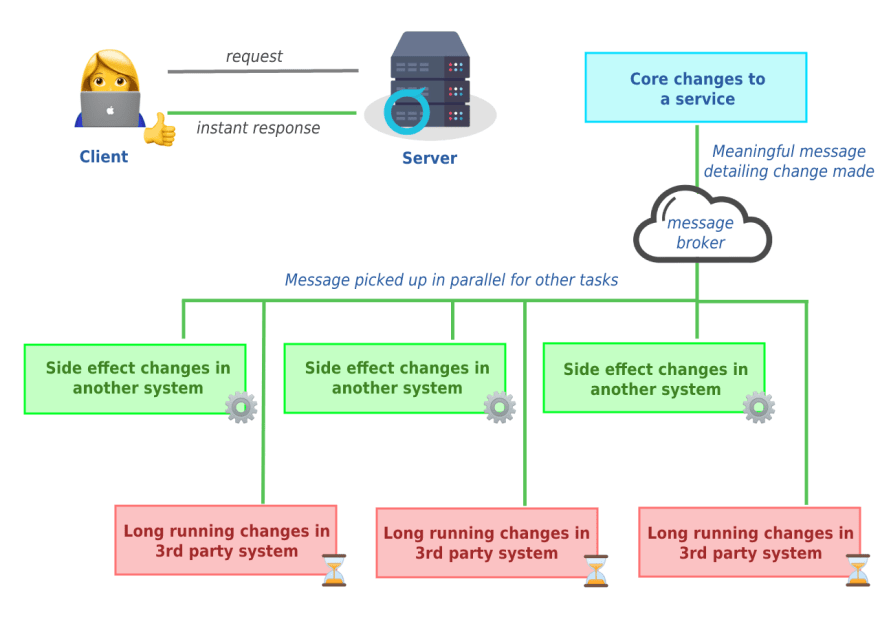
Whenever a client expresses some intent to the API by making a request to it, this intent can create follow-up tasks. These tasks do not need to be handled synchronously, i.e. they do not need to be handled while processing the initial request. Instead, we put a message about this intent onto the message queue where it can be picked up asynchronously by another process and handled independently from the original request.
Problem
But with great opportunities comes great responsibility. Message processing is very important and critical for our business. Some messages could expire without being consumed or inconsistent with queue restricted arguments. In theory, this should not happen or might happen in a very rare case. But as we are working with customers data, we do not want to lose important messages. To keep dead messages saved in the message broker and do not stuck them in the original queue, we are using dead-letter feature.

Messages are published to exchange and can be sent to multiple queues depending on the routing key. As you can see from the image above, we used the same dead-letter scheme as for the original queues, so dead messages may end up in the wrong dead-letter queues. It is not very critical if you pick up dead messages manually (considering that they are rare), but nevertheless, it is still strange to find these messages in the wrong place.
To solve this problem, we need to add a new argument to the properties of the queues, it is x-dead-letter-routing-key and it should be unique. As a unique value for the routing key, we can use the queue name itself. This idea brought our team one step closer to a good solution: we don’t need a dead-letter exchange anymore 🎉. To simplify it, we can use default nameless exchange "" with the dead-letter queue as the routing key and it will forward the message directly to the proper queue.

Unfortunately, doing everything is not as easy as writing or talking about it 😒. To maintain the consistency and stability of the message broker, the RabbitMQ does not allow changing the arguments of already existing queues.
Deployment preparation
So, RabbitMQ does not allow you to change queue arguments in the runtime, so the only possible way to do it by removing queues and re-creating them again with updated arguments. But it is not possible in production, as we might lose some messages when they already removed, but new ones still do not exist. To solve this problem we need to introduce temporary queues to handle these messages, while old queues will be removed. For a simple system, this will be possible with 4 releases:
- Create temporary queues, but do not handle messages from them for now.
- Switch to the new queues and remove old queues. At this step, we already have a properly configured queues, but names are different. To return to old names, we need to do the same steps again.
- Create new queues with old names, but with updated arguments. Do not consume messages from them for now.
- Switch to the new queues with updated arguments.

4 releases, not a few, right? This requires not only a lot of small work, but also attention to make sure everything went right every time. How can we reduce them? 🤔
The simplest thing we can do is agree to rename the queues. This will reduce the number of releases by 2 times, since we will not need to rename them back. This was acceptable to us, and we even got more of it as we improved the message handling process. But that’s a completely different story 😉.
What else can you do? Enabling consumers and message handling in the new queues right away will reduce release count to only one, but we should accept the risk of duplicated messages when new queues already created but old ones are still processing.
At this point, I was stopped by the teammate, because I did not take into account the process of our deployment. We have blue-green deployment process, it’s when you have multiple instances of the same thing. And when you deploy, you take one down, upgrade, then put it up, then take the other one down to upgrade. This guarantees there is something always up. In our case, this means there is always a consumer there.
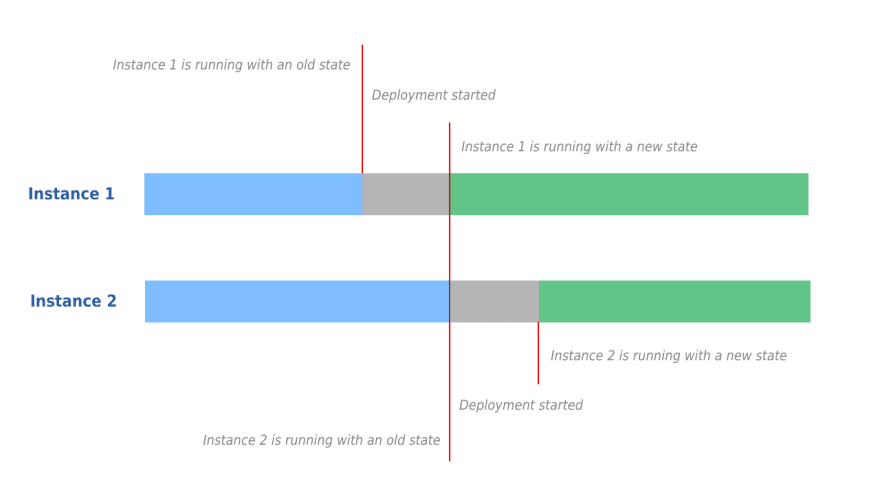
So, messages can definitely be duplicated if deployed during business hours. Deployment takes several minutes, which means that both old and new queues will be active for several minutes.
Time to analyze and decide whether it is safe to deploy the application at night (and do we really want to do it 🙂) when the message flow is low, or it is worth implementing a third-party service like a Redis to check if the message has already been processed by some consumer, old or new.
Release
The easiest way to check the load on our message broker is to check the number of logs by day of the week and time. Since we are a highly focused company working only in Germany, we have a very low message load from late evening to early morning.

It is not such a big highload as it could be, so we can accept the risk that some messages may be duplicated, but even if this happens, their number will be extremely small and we can manually solve them. This will save the resources and time that would be required for two releases.
After trying to release after midnight we found out that we couldn’t do it at night. Some of our third-party services are not available, so the container simply cannot be booted. Well, it was worth trying once, now we know it for sure. Nighttime for sleeping 😴.
But we can still do it late in the evening or early in the morning. One has only to pay attention to the RabbitMQ load.


We made the decision to press the release button early in the morning after a good night’s sleep. This time everything went fine and there were no duplicates.
It was not an easy way to solve this problem, but it was worth it. Solving this problem, our team and I learned a lot of interesting things about message consuming and deployment processes. Now it is even better than before, with correct queue settings and decoupled message handling 😎.
TL;DR
- RabbitMQ does not allow to rename queues or change queue arguments;
- to change something in the queue, you have to remove it and re-create;
- to re-create it safe, you need to use temporary queues;
- stable system could be run under multiple instances, so be aware of duplicated messages between old queues and new queues;
- if your business is tied to one timezone and is not high loaded at night, it is acceptable to have duplicated messages instead of over-engineering your consumers.
Leave a Reply