Author: Sergey Podgornyy
-
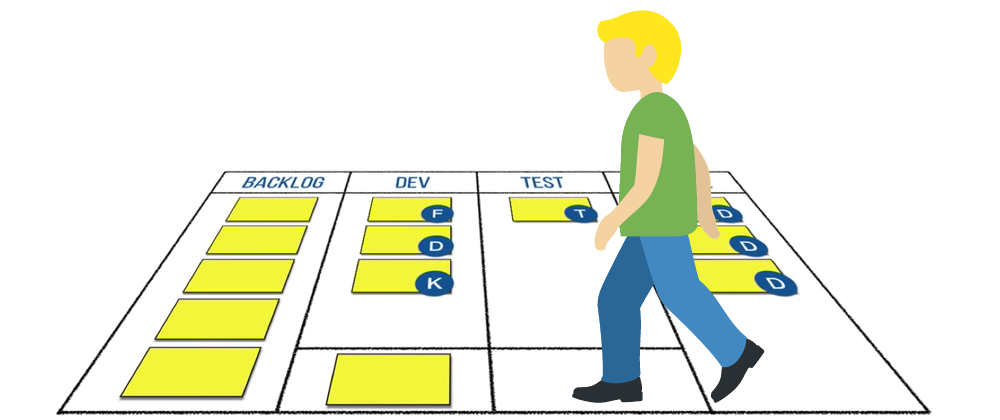
How We Transformed Our Daily Meetings for the Better
Transform your meetings with ‘Walking the Board’ inspired by ‘Development That Pays.’ Discover how we made stand-ups more collaborative, efficient and focused on team success. Explore actionable insights to revitalize your daily meetings and enhance teamwork.
-

Migrating from Self-Managed RabbitMQ to Cloud-Native AWS Amazon MQ: A Technical Odyssey
In the ever-evolving world of cloud-native solutions, it can be a daunting task to maintain message brokers. For a while, our team was responsible for a self-managed RabbitMQ instance. While this worked well initially, we encountered challenges in terms of maintenance, version updates, and data recovery. This led us to explore Amazon MQ, a fully…
-
How and why we updated RabbitMQ queues on production
In this article, I would like to share with you and the whole internet our experience of dealing with RabbitMQ Live updates. You will learn some details about our architecture and use cases. Let’s start from the simplest… Why do we need RabbitMQ in our business? Our Architecture As a health insurance company, our business…
-

Attending GopherCon online
2020 will be remembered for a very long time by the quarantine and the accompanying restrictions. All events where there is a crowd of people have been cancelled and we are trying to adhere to all recommendations. It would seem that this year’s conference would be impossible. But tough times await new solutions, and now…
-

Bulgaria PHP Conference 2019
Let’s talk about organization, preparation and venue first. From my point of view, the organizers did a lot to make this conference great, at least they tried to do their best. The conference, same as the workshop took place in the very center of the city, in the biggest public hall. It was quite easy…